
Filevine provides multiple data extraction options, including the report builder, Periscope, and the Data Connector. However, for customers who require “real time” data backup and reporting across large stores of data, additional options may be needed.
Filevine data is accessible via our open API, triggered by webhooks from updates to various Filevine objects (projects, contacts, sections, etc.). Combined with the daily feeds currently available through the Data Connector, webhook-triggered feeds can be used to create high-concurrency warehousing. The following process leverages our API and webhook capabilities via Workato to send data to S3 or Azure Blob Storage whenever changes are made in Filevine.
Configuring Your Cloud Storage Repository
The first step is to ensure that you have a cloud storage account that can receive CSVs from the Filevine API. The two options that are already compatible with the data connector (thereby simplifying the process for combining intraday data to daily feeds from the data connector) are AWS S3 and Azure Blob Storage. For instructions on how to set up accounts on either service, please visit the links below:
- AWS S3
- Azure Blob Storage (These instructions detail how to set up an Azure account with the necessary ISU compatibility with Workato. The same setup will work for non-middleware implementations. The following links provide information about configuring connection strings and naming and reference conventions of Azure Blob Storage.)
Webhooks
For every Filevine data object that is required for warehousing, customers will need to establish a subscription to the associated webhook (see this link for payload schemas and available events). All Filevine objects have webhooks triggered by standard events like created, updated or deleted. Standard Filevine data objects include:
- Projects
- Contacts
- Static sections (or forms as they are known in the API)
- Collection sections
There are, of course, other objects (e.g., documents, deadlines, notes, tasks among others); however, most of these other objects represent data that (1) already have good analytical tooling in app (ex. tasks), or (2) are not relevant for most analytics or business continuity purposes (ex. documents). Customers should be judicious in how many webhook events and API calls they require in implementing this solution.
API Calls & Workato Configuration
Once the full list of required webhooks has been determined, separate API calls for each must be made to retrieve data payloads for each object. These payloads can then be passed through as CSVs to S3 or Azure as files representing the change to data. Below is an example of a Workato recipe that passes a CSV to Azure for a Case Summary static section when any event occurs on the section:
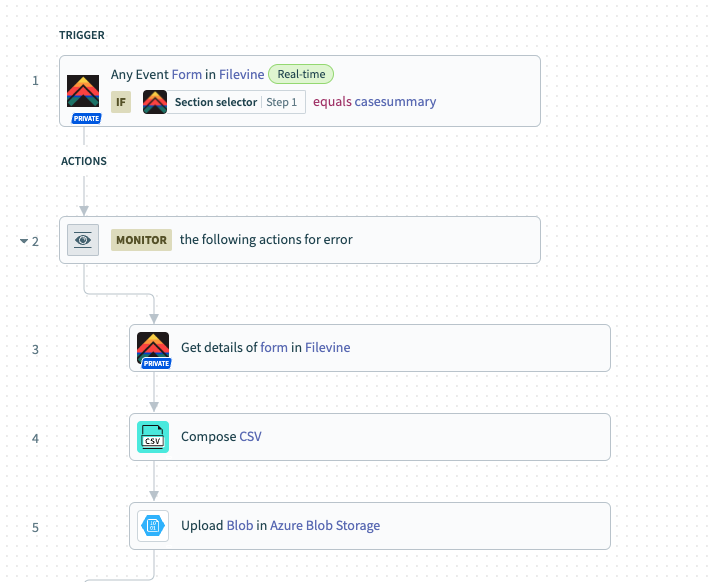
Note: In the “Compose CSV” step, every applicable field must be included in the CSV schema.
This approach renders individual CSVs to represent individual events occurring within app, rather than taking a snapshot of the current state of the data in Filevine, as does data connector. This distinction matters for a few reasons: (1) this intraday approach renders A LOT of data, (2) as soon as another action on the same Filevine object is taken, the data is now obsolete and should be removed, and (3) these intraday CSVs necessarily create data duplication with what is created in data connector.
Data ETL
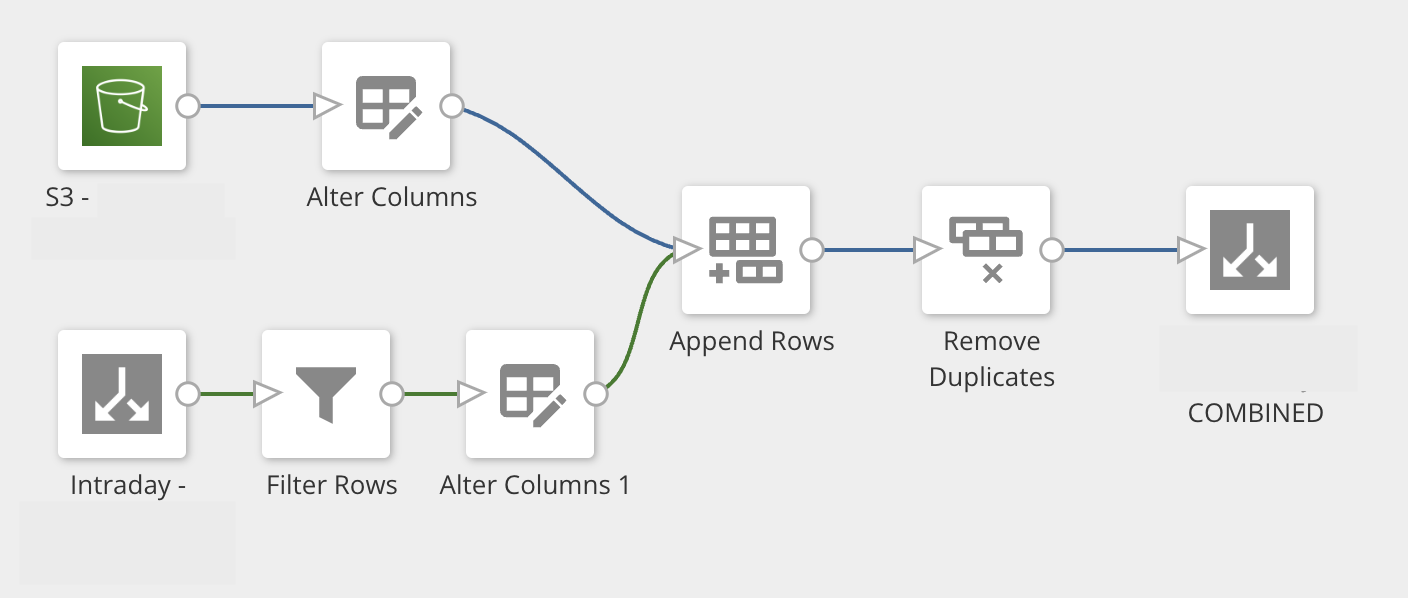
Once CSVs are hydrated to the cloud account, customers can process data warehousing in a number of ways. Appending and removing duplicates is the easiest way to do this in Domo (shown below; the secondary table in the append has the record that won’t be removed in the “Remove Duplicates” step).
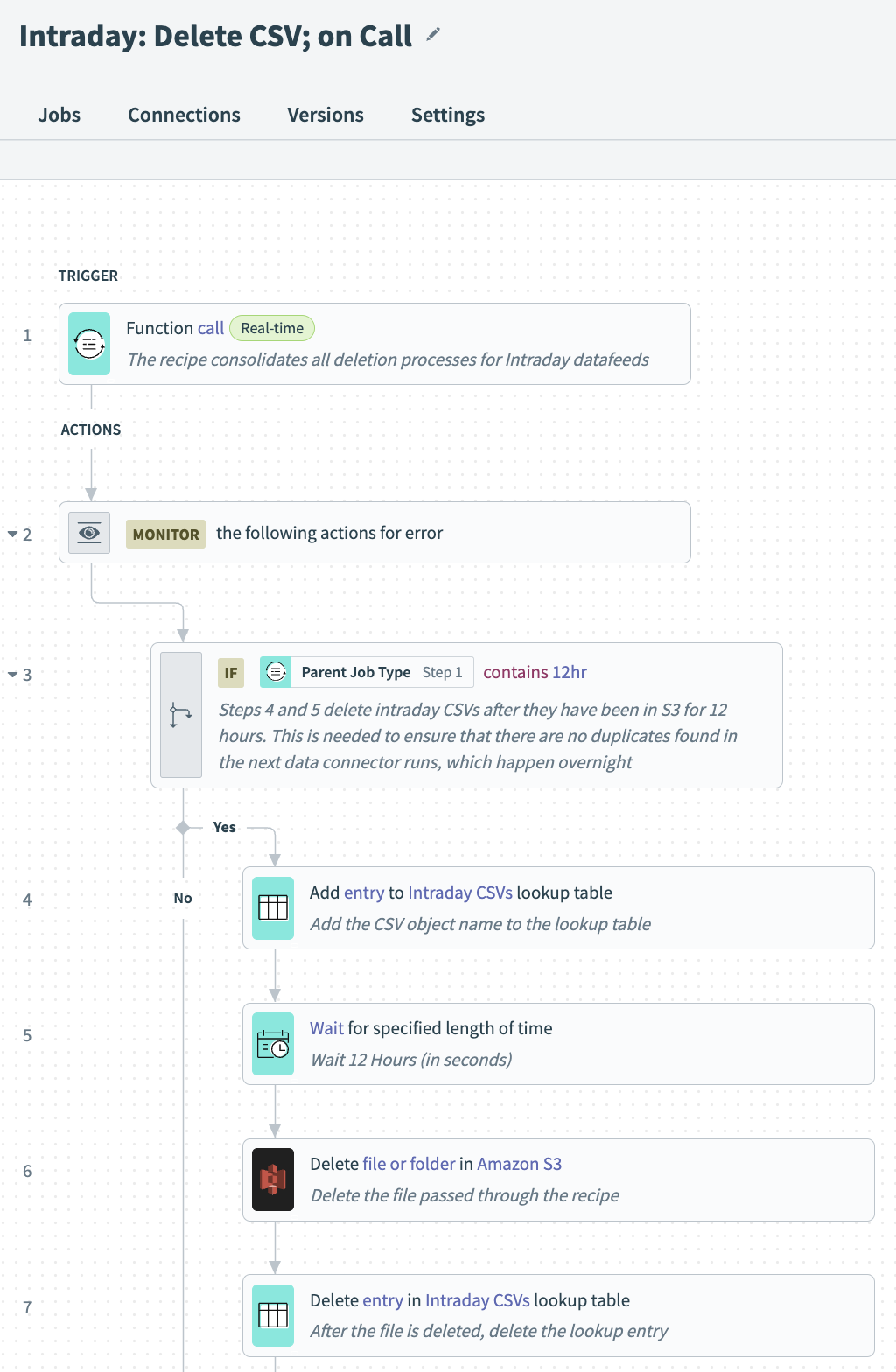
Additionally, to remove duplication of data, the process must include steps to delete CSVs (1) after 1 day, so as to not conflict with the daily feed, and (2) if there is a record for the primary key already.
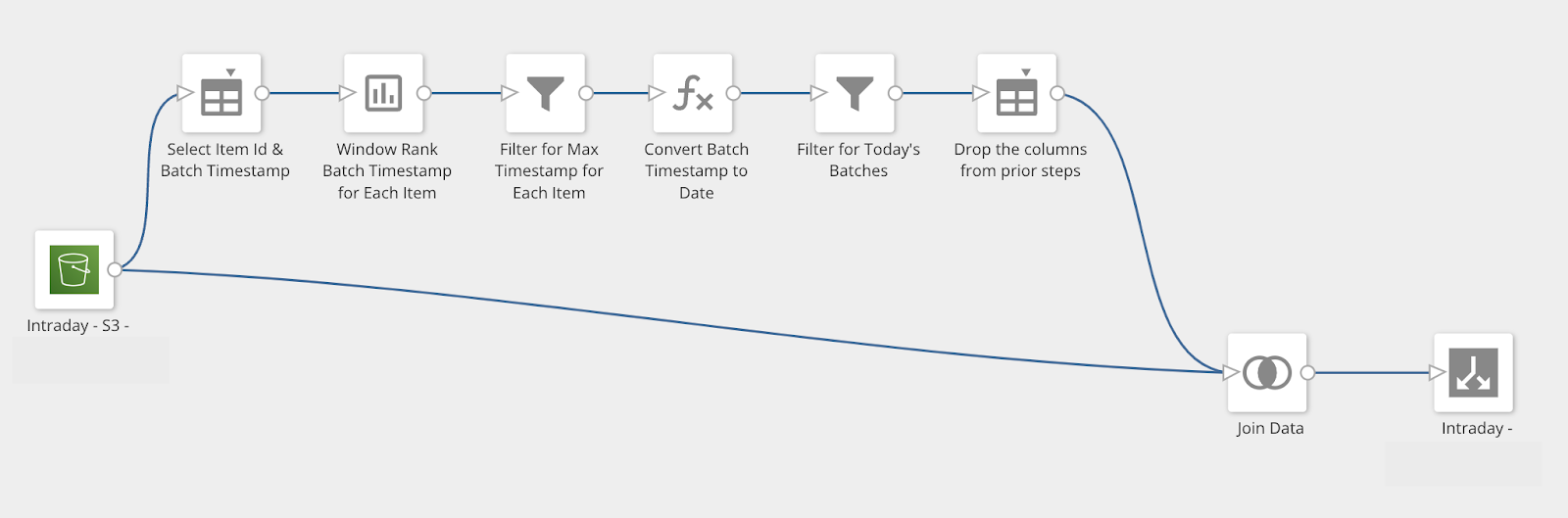
Comments
0 comments
Article is closed for comments.